 会员投稿
会员投稿 手机版
手机版
北京大学aiXcoder 团队一直致力于探索如何将深度学习与软件开发深度融合,推动软件开发的自动化。2024年4月,aiXcoder开源了自研代码大模型 aiXcoder-7B,成为这一领域的一次重要贡献,旨在将代码的抽象语法树(AST)结构与大规模预训练结合,以提升模型对代码结构和上下文的理解能力。
近期,该篇论文被软件工程领域国际顶级会ICSE 2025收录(International Conference on Software Engineering是软件工程领域最具影响力的国际学术会议之一),将于4月27日-5月3日赴加拿大渥太华参会分享研究成果。
此次论文录用不仅是对 aiXcoder 7B 代码大模型技术前瞻性和应用创新性的高度认可,更标志着该模型继成功落地企业并获各行业客户广泛认可后,再次于学术界获得权威肯定,充分彰显了以北大aiXcoder代表的国产AI Coding在推动软件工程发展中的前瞻性引领作用。

aiXcoder 7B是2024年4月正式推出并开源的全自研代码大模型,基于1.2T高质量代码数据集、专门结合代码特性、针对代码相关任务进行了预训练,具有易部署、易定制、易组合等特性。在多个主流测评集上,aiXcoder 7B代码生成与补全能力超越同级别及更高参数规模的开源模型。
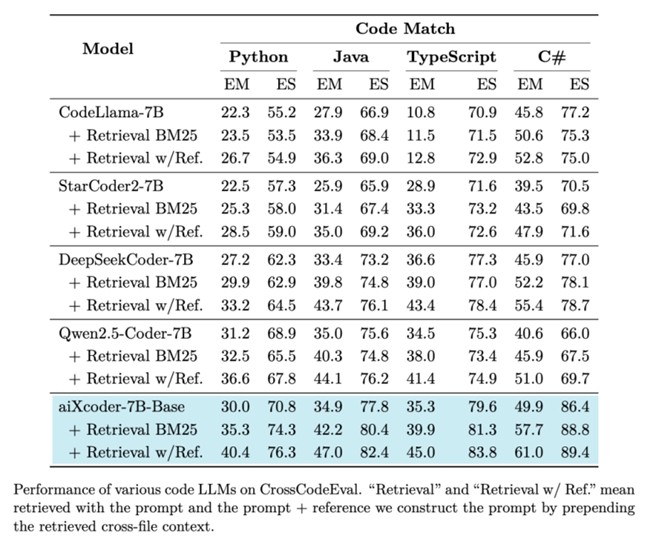
例如,在贴近真实开发场景的评测集CrossCodeEval上,aiXcoder 7B超越了晚于其近半年发布、基于5.5T token训练的Qwen2.5-Coder-7B,以及DeepSeekCoder-7B、CodeLlama-7B等同级别参数规模的开源模型,一举拿下最好效果。
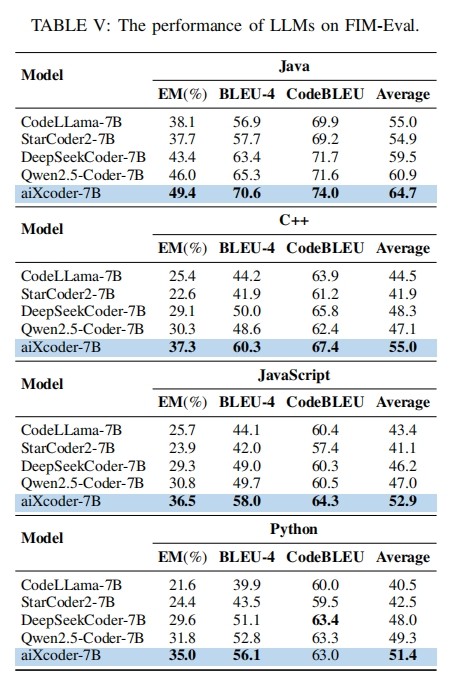
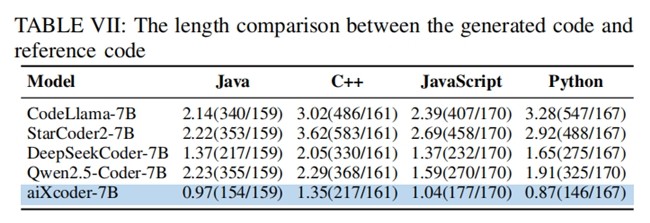
为了测试7B在企业真实开发场景下的代码处理能力,aiXcoder基于16000多条来自真实开发场景的数据,构建了一个大规模测评代码生成补全数据集,并对多个大模型进行测评。结果显示,aiXcoder 7B不仅在代码生成与补全方面效果最好,且生成的代码更加简洁,更接近人类编码风格。
凭借卓越的性能和技术实力,aiXcoder 7B很快在全球开发者中获得广泛关注和验证。其开源的Base版迅速在GitHub上2800多万项目中脱颖而出,一周内Star数超过2k,并登上HuggingFace趋势榜TOP30。众多开发者围绕aiXcoder 7B展开热烈讨论,积极探讨本地部署、配置等话题,并分享部署经验及适配多种硬件的尝试。
aiXcoder 7B的发布与开源不仅代表技术层面的重大突破,更为企业实现大模型的低成本部署和领域化应用带来全新解决方案。
在aiXcoder看来,利用公开代码数据训练的大模型无法充分支持特定行业领域的软件开发需求,还需要进一步面向企业进行深度领域化训练,让大模型充分学习企业领域化知识。同时,结合提示词工程、RAG和Agent等技术,进一步将企业特有的业务流程、软件开发框架、编码规范和常用开发工具等和大模型相融合,确保模型生成的代码在逻辑和风格上更符合企业特点。目前,aiXcoder 7B已在金融、航空航天、软件服务、智能制造等多行业领域实现落地应用,有效帮助企业以最小算力资源落地领域化代码大模型。
aiXcoder计划于2025上半年推出7B 2.0,它是在7B 1.0的基础上经过一个新颖的对齐训练得到。该对齐训练有效地将模型对齐到真实软件开发场景中的上下文形式,显著增强模型在多种编程语言环境上的代码补全准确度。从初步实验情况来看,在Python的多行补全实验中,aiXcoder 7B 2.0相较之前在Exact Match(完全匹配)指标上取得了13个点的绝对提升。
未来,aiXcoder将继续提升技术和产品的创新能力,赋能软件开发全生命周期,帮助更多企业提升软件开发效率和质量、加速产品迭代与创新、构建数字化进程中的核心竞争力。(心吾)











